The Gedcom parser library internals
The intention of this page is to provide some explanation
of the gedcom parser, to aid development on and with it. First,
some practical issues of testing with the parser will be explained.
Testing
Basic testing
You should be able to perform a basic test using the commands:
However, since the output that
For the first issue, the UTF-8 capable terminal, the safest bet is to use
For the second issue, you'll need the ISO 10646-1 fonts. These come also with XFree86 4.0.x.
The way to start
For the ANSEL test file (
This concludes the testing setup. Now for some explanations...
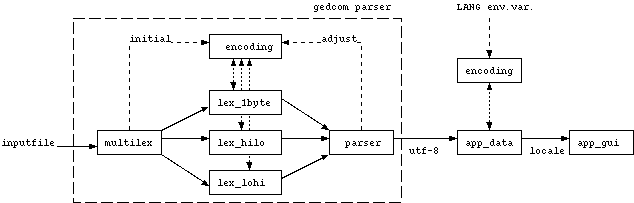
The parser is based on
For each recognized statement in the GEDCOM file, the parser calls some callbacks, which can be registered by the application to get the information out of the file.
This basic description ignores the problem of character encoding.
GEDCOM defines three standard encodings:
Index
- Testing
- Basic testing
- Preparing for further testing
- Testing the parser with debugging
- Testing the lexers separately
- Structure of the parser
Testing
Basic testing
You should be able to perform a basic test using the commands:If everything goes OK, you'll see that some gedcom files are parsed, and that each parse is successful. Note that some of the used gedcom files are made by Heiner Eichmann and are an excellent way to test gedcom parsers thoroughly../configure
make
make check
Preparing for further testing
Some more detailed tests are possible, via thetestgedcom program
that is generated by make. However, since the output that
testgedcom generates
is in UTF-8 format (more on this later), some preparation is necessary
to have a full view on it. Basically, you need a terminal that understands
and can display UTF-8 encoded characters, and you need to proper fonts
installed to display them. I'll give some advice on this here,
based on the Red Hat 7.1 distribution that I use, with glibc 2.2 and XFree86
4.0.x. Any other distribution that has the same or newer versions
for these components should give the same results.For the first issue, the UTF-8 capable terminal, the safest bet is to use
xterm in its unicode mode (which is supported by
the xterm coming with XFree86 4.0.x). UTF-8 capabilities
have only recently been added to gnome-terminal, so probably
that is not in your distribution yet (it certainly isn't in Red Hat 7.1).For the second issue, you'll need the ISO 10646-1 fonts. These come also with XFree86 4.0.x.
The way to start
xterm in unicode mode is then e.g.
(put everything on 1 line !):This first sets theLANG=en_GB.UTF-8 xterm -bg 'black' -fg 'DarkGrey' -cm -fn '-Misc-Fixed-Medium-R-SemiCondensed--13-120-75-75-C-60-ISO10646-1'
LANG variable to a locale that
uses UTF-8, and then starts xterm with a proper Unicode font.
Some sample UTF-8 plain text files can be found
here . Just cat them on the command line
and see the result.Testing the parser with debugging
Given the UTF-8 capable terminal, you can now let thetestgedcom
program print the values that it parses. An example of a command
line is (in the top The./testgedcom -dg t/input/ulhc.ged
-dg option instructs the parser to show its own debug
messages (see ./testgedcom -h for the full set of options).
If everything is OK, you'll see the values from the gedcom file,
containing a lot of special characters.For the ANSEL test file (
t/ansel.ged), you have to set
the environment variable GCONV_PATH to the ansel
subdirectory of the top directory:export GCONV_PATH=./ansel
./testgedcom -dg t/input/ansel.ged
Testing the lexers separately
The lexers themselves can be tested separately. For the 1-byte lexer (i.e. supporting the encodings with 1 byte per characters, such as ASCII, ANSI and ANSEL), the command would be (in thegedcom subdirectory):make lexer_1byte
t/input/allged.ged
test file. Simply cat the file through the lexer on standard input
and you should get all the tokens in the file. Similar tests can be
done using make lexer_hilo and
make lexer_lohi
(for the unicode lexers). In each of the cases you need to know
yourself which of the test files are appropriate to pass through the lexer.This concludes the testing setup. Now for some explanations...
Structure of the parser
I see the structure of a program using the gedcom parser as follows:
The parser is based on
lex/yacc, which means that a module generated by lex
takes the inputfile and determines the tokens in that file (i.e. the smallest
units, such as numbers, line terminators, GEDCOM tags, characters in GEDCOM
values...). These tokens are passed to the parser module, which is
generated by yacc, to parse the syntax of the file, i.e. whether the tokens
appear in a sequence that is valid. For each recognized statement in the GEDCOM file, the parser calls some callbacks, which can be registered by the application to get the information out of the file.
This basic description ignores the problem of character encoding.
Character encoding
Refer to this page for some introduction on character encoding...GEDCOM defines three standard encodings:
- ASCII
- ANSEL
- UNICODE (assumed to be UCS-2, either big-endian or little-endian: the GEDCOM spec doesn't specify this)
$Id: parser.html,v 1.10 2002/01/20 13:32:26 verthezp Exp $
$Name: R0_90_0 $